Questa WebApp nasce da una richiesta concreta di un ente: gestire in modo strutturato e affidabile il flusso documentale legato ai solleciti tributari di un ente comunale, un contesto in cui i volumi sono significativi, i dati anagrafici devono essere precisi e ogni documento deve essere rintracciabile senza margine di errore.
Il sistema copre l'intero ciclo operativo, dall'importazione massiva dei dati fino alla consultazione amministrativa. Gli operatori possono caricare file CSV con migliaia di record, che vengono processati con logica di upsert e deduplicazione automatica: il sistema riconosce i record già presenti, aggiorna quelli modificati e inserisce i nuovi, senza duplicazioni e senza perdita di dati. A ogni record vengono poi associati i relativi PDF — notifiche, ricevute, documenti di spedizione — attraverso un meccanismo di riallineamento automatico che incrocia i dati anagrafici e documentali importati, evitando associazioni errate anche in presenza di dataset eterogenei o parzialmente inconsistenti.
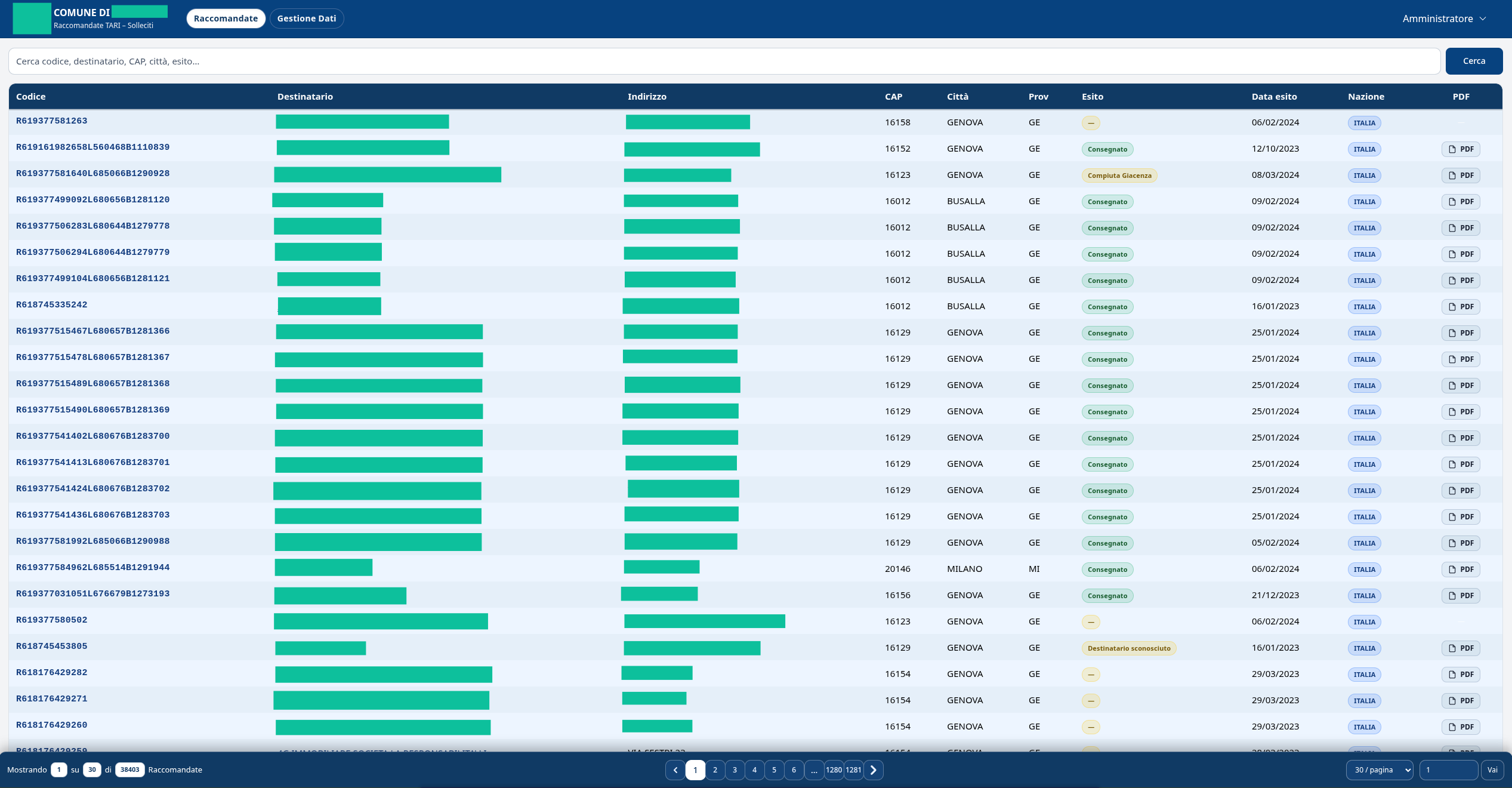
L'interfaccia amministrativa permette la ricerca e la consultazione dei record per diversi parametri, la verifica dello stato di ogni pratica e l'accesso diretto ai documenti allegati. Sono inclusi anche strumenti di supporto alla manutenzione: log di importazione, report sulle anomalie riscontrate, funzioni di verifica della coerenza tra dataset e archivio documentale.
Sul fronte infrastrutturale, il progetto ha richiesto un lavoro non banale di ottimizzazione e troubleshooting. La gestione di upload pesanti, il parsing di CSV con migliaia di righe e le operazioni intensive sui PDF imponevano limiti che l'ambiente di produzione — Nginx, PHP-FPM, Plesk — non era configurato per reggere nella sua forma predefinita. Ho intervento su timeout, limiti di memoria, configurazioni di processo e parametri di esecuzione per rendere il sistema stabile e performante in condizioni reali, non solo in locale.
Il progetto è costruito su Laravel 12 con PHP 8, Nginx e PHP-FPM come stack applicativo, Plesk per la gestione dell'ambiente server e Vite per la build degli asset frontend. È stato pensato fin dall'inizio con un'architettura generalizzabile: le stesse logiche di importazione, associazione documentale e gestione archivio possono essere adattate ad altri enti o a qualsiasi flusso documentale strutturato ad alto volume.